Redacción TJ OST. El culebrón de Sam Altman y Open AI ha generado un juego de intereses donde se dilucidan «miles de billones de dólares». Para justificar lo injustificable han aparecido cortinas de humo y especulaciones. Entre ellas e investigadores «una hipotética carta de investigadores de Open AI «expresando preocupaciones sobre un descubrimiento que podría amenazar a la humanidad».
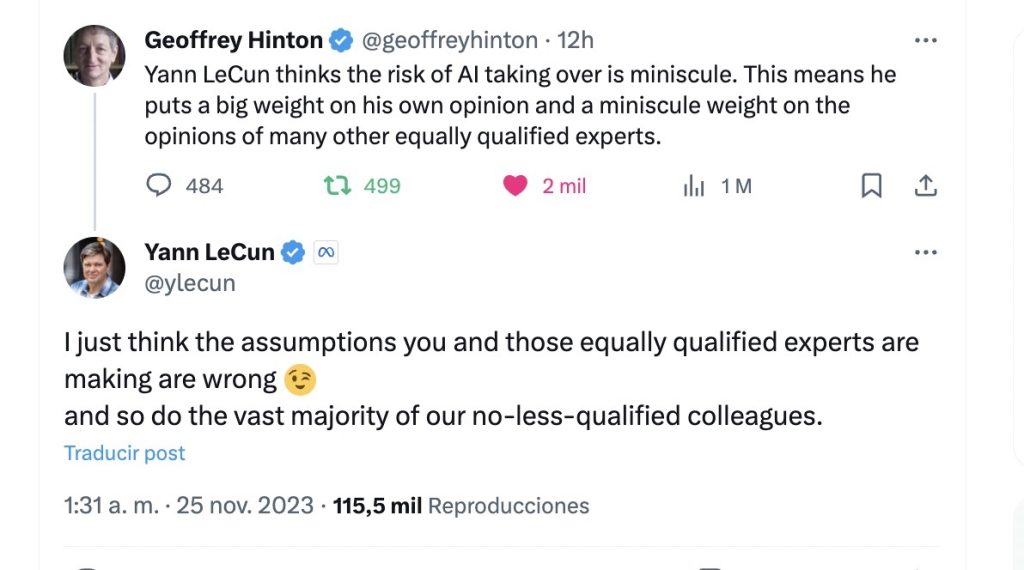
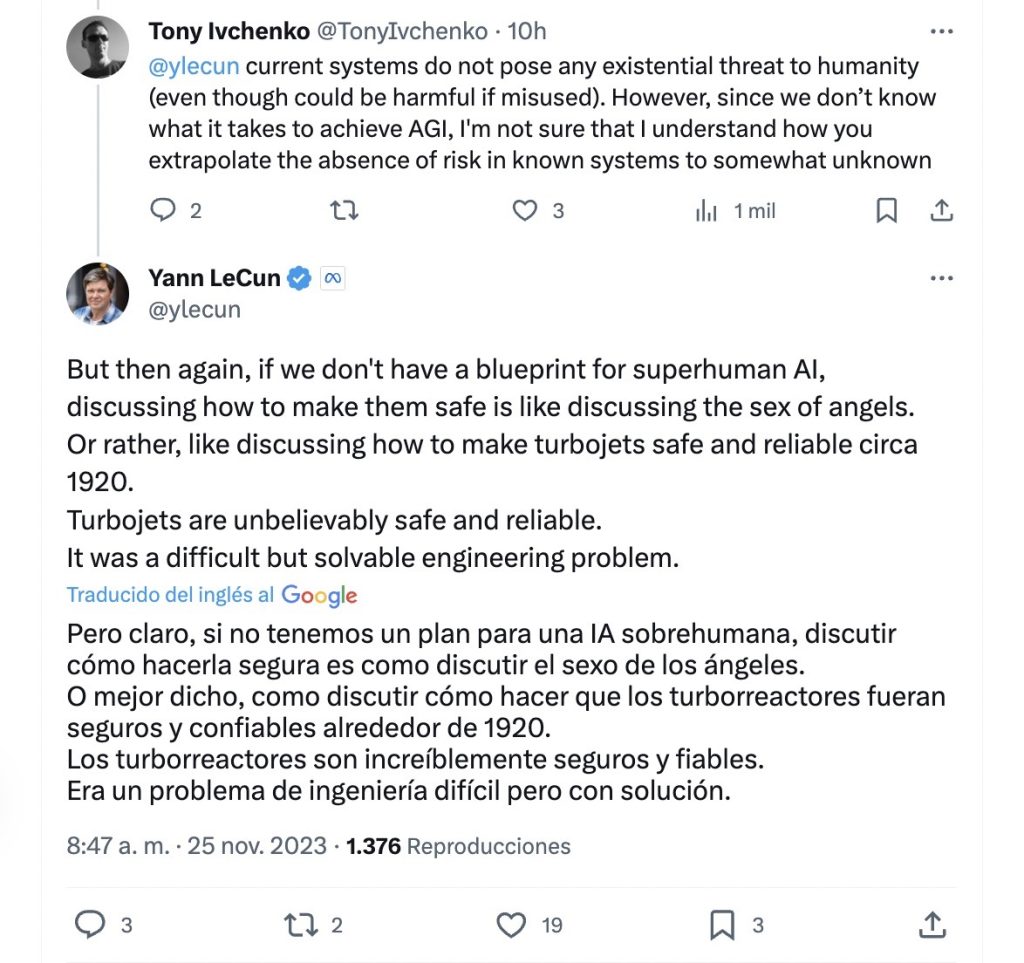
Esto ha dado pie a los «extincionistas de la IA» a proclamar riesgos y especulaciones. Geoffrey Hinton, Yann LeCun y Andrew Ng han intercambiado mensajes en la red X (antigua Twitter). Abajo del todo recogemos las imágenes de los twits y sus enlaces.
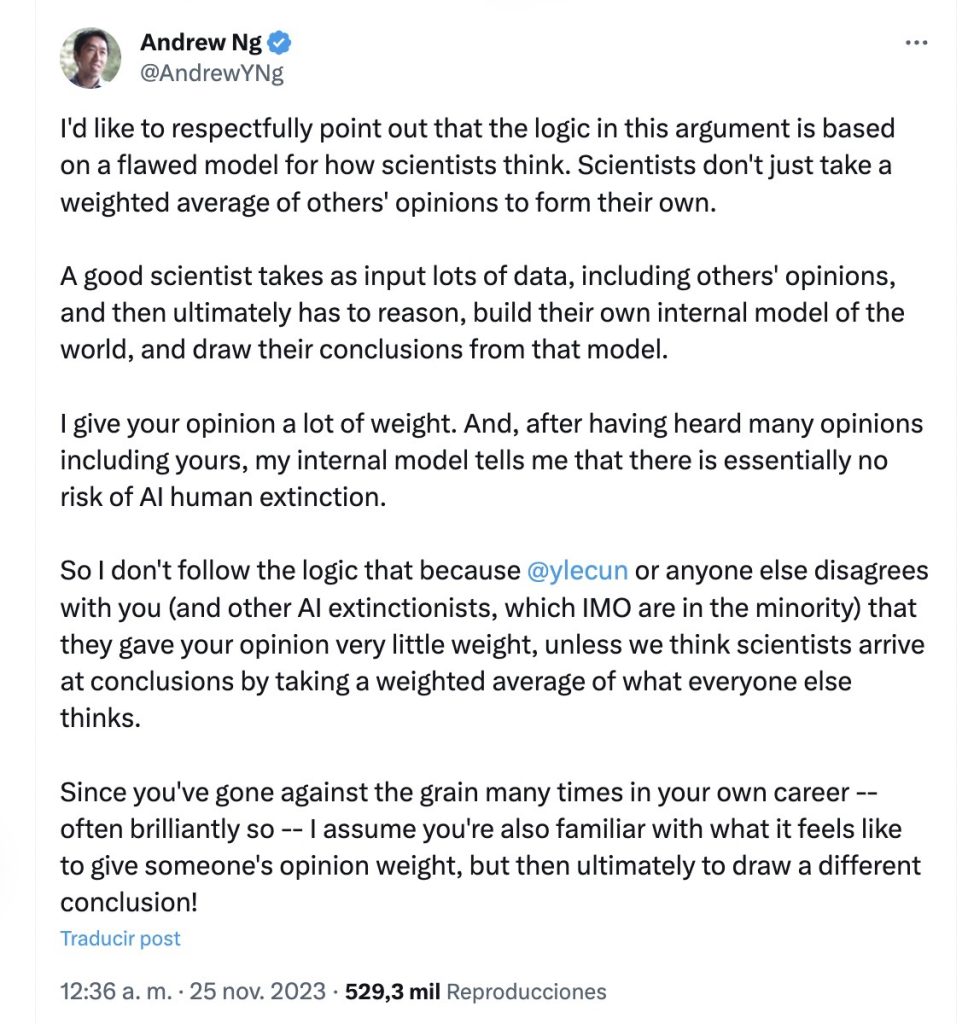
Quizás es resaltable la respuesta de Andrew Ng que traducimos a continuación. Andrew Ng (Universidad de Stanford, Coursera…) es para nosotros una de las voces más autorizada en estos temas:
Respuesta de Andrew Ng
«Me gustaría señalar respetuosamente que la lógica de este argumento se basa en un modelo defectuoso de cómo piensan los científicos. Los científicos no se limitan a tomar un promedio ponderado de las opiniones de los demás para formar la suya propia.
Andrew Ng
Un buen científico toma como entrada muchos datos, incluidas las opiniones de otros, y luego, en última instancia, tiene que razonar, construir su propio modelo interno del mundo y sacar conclusiones a partir de ese modelo.
Le doy mucho peso a tu opinión. Y, después de haber escuchado muchas opiniones, incluida la suya, mi modelo interno me dice que esencialmente no existe riesgo de extinción humana de la IA.
Así que no sigo la lógica de que debido a que Yann LeCun o cualquier otra persona no está de acuerdo contigo (y otros extincionistas de la IA, que en mi opinión son una minoría), le dieron muy poco peso a tu opinión, a menos que pensemos que los científicos llegan a conclusiones tomando un promedio ponderado de lo que todos los demás piensan».
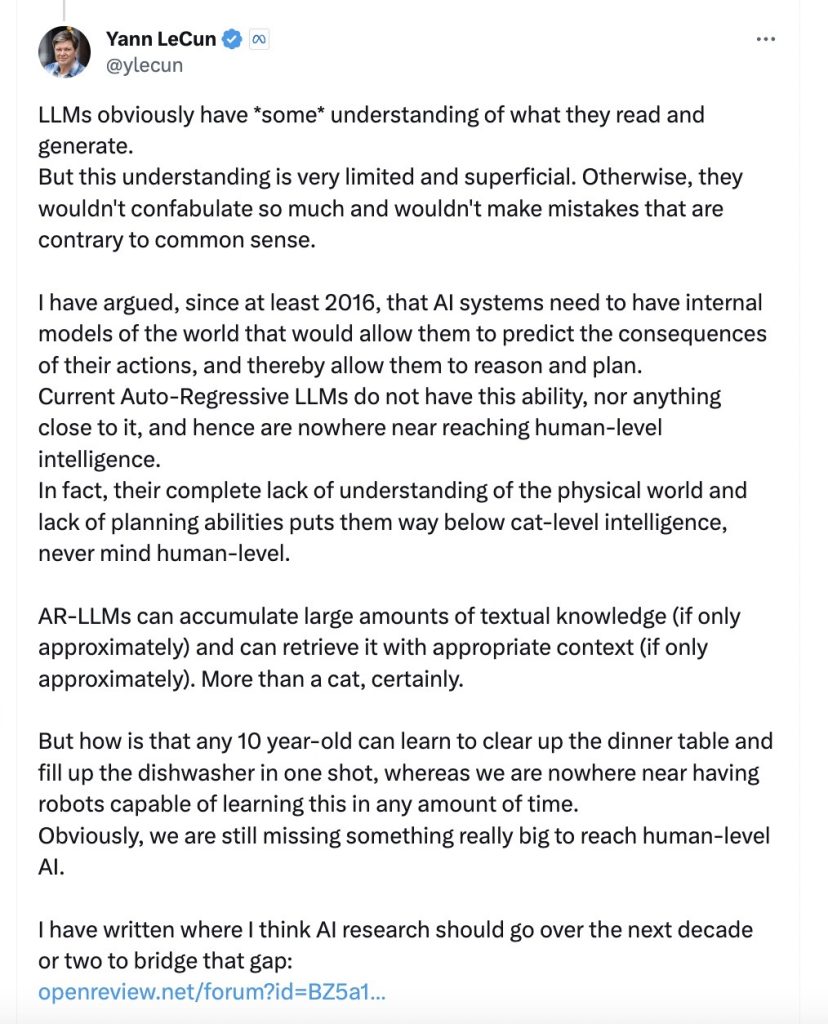
Respuesta de Yann LeCun
Los LLM obviamente tienen *algo* de comprensión de lo que leen y generan. Pero esta comprensión es muy limitada y superficial. De lo contrario, no confabularían tanto y no cometerían errores contrarios al sentido común.
Yann LeCun
He sostenido, al menos desde 2016, que los sistemas de IA necesitan tener modelos internos del mundo que les permitan predecir las consecuencias de sus acciones y, por lo tanto, razonar y planificar. Los LLM autorregresivos actuales no tienen esta capacidad, ni nada parecido, y por lo tanto no están ni cerca de alcanzar una inteligencia a nivel humano. De hecho, su total falta de comprensión del mundo físico y su falta de capacidad de planificación los sitúa muy por debajo del nivel de inteligencia de los gatos, y mucho menos del nivel humano.
Los AR-LLM pueden acumular grandes cantidades de conocimiento textual (aunque solo sea aproximadamente) y pueden recuperarlo con el contexto apropiado (aunque solo sea aproximadamente). Más que un gato, sin duda.
Pero, ¿cómo es posible que cualquier niño de 10 años pueda aprender a recoger la mesa y llenar el lavavajillas de una sola vez, mientras que estamos muy lejos de tener robots capaces de aprender esto en cualquier cantidad de tiempo?
Obviamente, todavía nos falta algo realmente grande para alcanzar la IA a nivel humano. He escrito dónde creo que debería avanzar la investigación de la IA durante la próxima década o dos para cerrar esa brecha: https://openreview.net/forum?id=BZ5a1r-kVsf… Todas mis charlas de los últimos años han versado sobre «arquitecturas de IA impulsadas por objetivos», que son un intento de cerrar esa brecha y al mismo tiempo hacer que los sistemas de IA sean controlables, seguros y subordinados a la humanidad. Por ejemplo este: https://www.youtube.com/watch?v=pd0JmT6rYcI

Humanos ingenuos… ante terminator…. 😊 Dalle-image